Linguistics Seminar: Numa Markee (UIUC)
- Sponsor
- Department of Linguistics
- Speaker
- Numa Markee
- Contact
- Sofya Styrina
- styrina2@illinois.edu
- Views
- 54
Title: How detailed do conversation analytic transcripts really need to be?
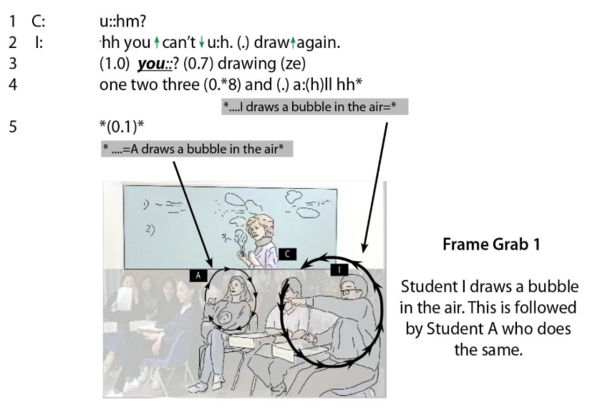
Abstract: The empirical data I use to answer the question I posed in my title come from an ESL class I videotaped some 25 years ago at an American university. The participants’ observably competent performance of talk suggest that class members lie on a continuum of true to low intermediate levels of discoursal proficiency. I use these data to show what kind of analytic purchase conversation analysts can gain from using “logocentric” transcription conventions developed in the early 1970s by Jefferson (2004). I then reanalyze these data by using the “visuocentric” transcription conventions (Mondada, 2016) developed over exhibittime by Goodwin (2017) and Mondada (2021). The fragment below exhibit the more granular, multimodal version of the data that I analyze in this talk (see Markee, in press).
I conclude that both sets of transcription conventions give us powerful insights into the organization of talk. However, the analysis based the Jeffersonian transcript is, in this particular case, empirically less adequate than the one based on its multimodal sibling because it is observably incomplete or, at worst, misleading.